机器学习
回归模型评估
案例一:鸢尾花分类
机器学习的优化算法
交叉熵
lightGBM
处理非平衡数据集的方法
AdaBoost
GBDT
XGBoost
决策树
线性回归
pytorch 优化器的使用
分类模型评估
损失函数
前馈神经网络
特征工程
分箱
评分卡实现过程
逻辑回归
本文档使用 MrDoc 发布
-
+
首页
分类模型评估
### 混淆矩阵 首先需要了解一下混淆矩阵,它是二分类模型评估的基础: | | 真实值为正 | 真实值为负 | | --- | --- | --- | | 预测值为正 | True Positive| False Positive | | 预测值为负 | False Negtive| True Negtive | 参数说明: - TP:`True Positive` 即预测为正,且预测正确 - FP:`False Positive` 即预测为正,但预测错误 - TN:`True Negtive` 即预测为负,且预测正确 - FN:`False Negtive` 即预测为负,但预测错误 > 第一个单词表示预测是否正确,第二个单词表示预测结果,可以认为两者均针对预测值。 ### 二分类评估指标 1. **准确率**:`预测正确的样本数,占所有样本数的比例` ``` Accuracy = (TP + TN)/(TP + FP + TN + FN) ``` 2. **精确率**:`预测为正且预测正确的样本数,占所有预测为正的样本数的比例` ``` Precision = TP / (TP + FP) ``` 3. **召回率**:`预测为正且预测正确的样本数,占所有真实值为正的样本数的比例` ``` Recall = TP /(TP + FN) ``` 4. **F1值**: ``` F1 = 2 * Precision * Recall /(Precision + Recall) ``` F1是一个综合指标,是`Precision和Recall的调和平均数`,因为在一般情况下,`Precision`和`Recall`是两个互补关系的指标,鱼和熊掌不可兼得,因此通过F1测度来综合进行评估。F1越大,分类器效果越好。 当`Precision = Recall = 1`时,`F1 = 1`达到最大值。如果任意一个值很小,那么分子就会很小,F1就不会大,便说明分类性能不好。 5. **ROC/AUC** 5.1 `参数定义` 真正率:TPR = TP / (TP + FN)预测为正且预测正确的样本,占所有真实值为正的样本的比例。公式与召回率一样。 假正率:FPR = FP / (TN + FP)所有负样本中,被错误识别为正样本的比例。又叫`误报率`,错误接收率。 5.2 `ROC曲线的定义` > 以FPR为x轴,TPR为y轴,通过不断改变`threshold`的值,通过计算获取到一系列的点(FPR,TPR),将这些点用平滑曲线连接起来就得到ROC曲线 参数`threshold`是正负样本分类的阈值,通常二分类模型中取0.5。但是在绘制ROC曲线过程中,我们需要如下操作: > **将所有样本的预测概率值从低到高排序,并将这些值依次作为`threshold`,然后计算对应的值(FPR,TPR),并在坐标图中绘制相应的点。最后加上两个`threshold`值0和1,分别可对应到(1,1), (0,0)两个点,将这些点连接起来即得到ROC曲线,点越多,曲线越平滑,而ROC曲线下的面积即为AUC。** 5.3 `ROC曲线的特点` - 一个好的分类器应该使得ROC曲线尽量位于左上位置,当ROC为(0,0), (1,1)两个点的直线时,分类器效果跟随机猜测效果一样; - ROC曲线下方的面积作为AUC,可以用AUC作为衡量分类器好坏的标准,AUC值越大越好,最理想的分类器AUC为1。当AUC为0.5时,分类器分类效果跟随机猜测效果一致; - ROC能很好的解决正负样本分布发生变化的情况,在正负样本分布发生变化的情况下,ROC能够保持不变; 5.4 `ROC曲线的特点2` 既然已经这么多评价标准,为什么还要使用ROC和AUC呢?因为ROC曲线有个很好的特性: > 当测试集中的正负样本的分布变化的时候,ROC曲线能够保持不变 在实际的数据集中经常会出现类不平衡(class imbalance)现象,即负样本比正样本多很多(或者相反),而且测试数据中的正负样本的分布也可能随着时间变化,而此时,ROC曲线却能够保持不变。 在下图中,(a)和(c)为ROC曲线,(b)和(d)为Precision-Recall曲线。(a)和(b)展示的是分类其在原始测试集(正负样本分布平衡)的结果,(c)和(d)是将测试集中负样本的数量增加到原来的10倍后,分类器的结果。可以明显的看出,ROC曲线基本保持原貌,而Precision-Recall曲线则变化较大。 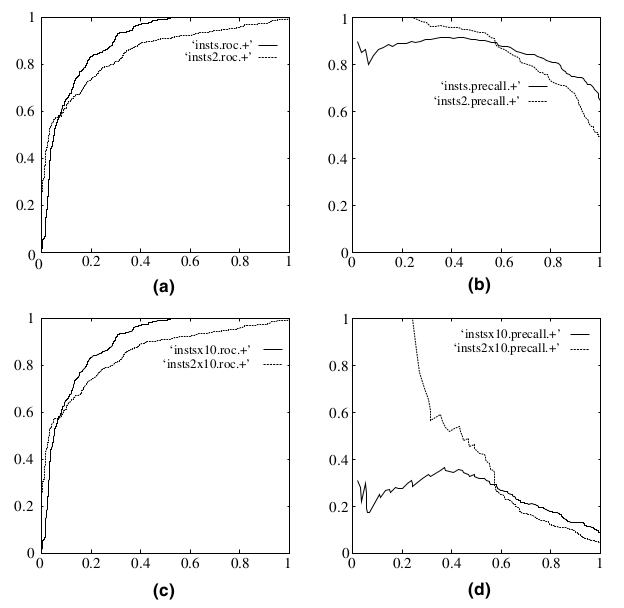 6. **TPR**:`预测为正且预测正确的样本,占所有真实值为正的样本数的比例,公式与召回率一样` ``` TPR = TP / (TP + FN) ``` 7. **FPR**:`所有负样本中,被错误识别为正样本的比例,也称为误报率` ``` FPR = FP / (FP + TN) ``` 8. **Gain**:`不同阈值时的精确率` 公式与精确率一样,但它描述的是不同阈值时的精确率,因此它是一条曲线; ``` Gain = TP / (TP + FP) # 与精确率一样 ``` 9. **Lift**:`相较于不利用模型时精确率的提升指数` 表示的是一个模型的预测能力优于随机选择的倍数,以1为界线,大于1表示该模型比随机选择有更`准确`的“响应”。 ``` Lift = Gain / [Positive / (Positive + Negative)] ``` 其中,`Positive / (Positive + Negative)`表示的是随机选择时有这样的概率获得正例。就好比一个箱子中有白球和黑球,随机抽取一个球是白球的概率。 10. **KS**:`表示模型对样本的区分度` > - 通过调整阈值可以得到很多FPR和TPR的值,KS曲线就是以阈值作为横轴,FPR描点形成一条曲线,TPR描点形成另一条曲线。 > - 可以看出KS曲线和ROC曲线类似,都是通过FPR和TPR描点画线获得。 > - KS值越大,表示模型能够将正、负样本区分开的程度越大,但是分隔并不一定表示正确。 > - 通常来讲,KS>0.2即表示模型有较好的预测准确性。 ``` KS = max(TPR - FPR) # TPR与FPR差值的最大值 ``` 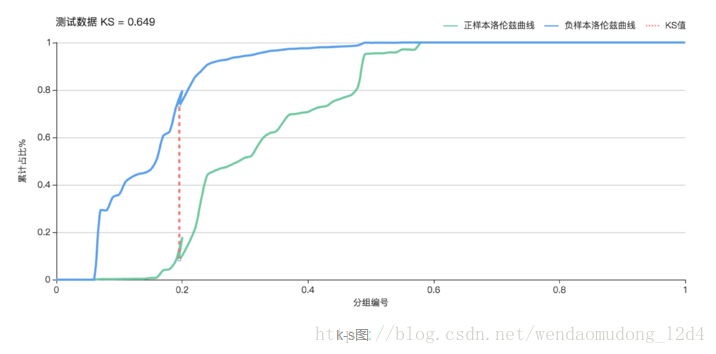 11. 一些说明 `Accaracy`和`Precision`作用相差不大,都是值越大分类器效果越好,但是有前提,前提就是样本是均衡的。如果样本严重失衡了,`Accuracy`不再适用,只能使用`Precision`。举个简单的例子,比如二分类问题为预测癌症的发生,显然在现实世界中,癌症人数在所有人数中的占比通常只是0.5%左右,即正负样本比例为1:200左右,此时一个分类器如果使用Accuracy作为评估指标,则分类器无需花太多功夫,分类器只用把样本全部清一色预测为正常,那么Accuracy也能达到99.5%的准确率,如此高的准确率,但却毫无任何意义,无法应用到实处,泛化能力极差。顾在样本失衡的情况下,Accuracy不再适用,通常使用Precision,同时该场景下ROC,可以用AUC。 ### 参考 > [二分类相关评估指标](https://blog.51cto.com/u_13977270/3399242) > [机器学习之分类性能度量指标](https://www.deeplearn.me/1522.html)
gaojian
2023年2月23日 17:16
分享文档
收藏文档
上一篇
下一篇
微信扫一扫
复制链接
手机扫一扫进行分享
复制链接
关于 MrDoc
觅思文档MrDoc
是
州的先生
开发并开源的在线文档系统,其适合作为个人和小型团队的云笔记、文档和知识库管理工具。
如果觅思文档给你或你的团队带来了帮助,欢迎对作者进行一些打赏捐助,这将有力支持作者持续投入精力更新和维护觅思文档,感谢你的捐助!
>>>捐助鸣谢列表
微信
支付宝
QQ
PayPal
Markdown文件
分享
链接
类型
密码
更新密码



