机器学习
回归模型评估
案例一:鸢尾花分类
机器学习的优化算法
交叉熵
lightGBM
处理非平衡数据集的方法
AdaBoost
GBDT
XGBoost
决策树
线性回归
pytorch 优化器的使用
分类模型评估
损失函数
前馈神经网络
特征工程
分箱
评分卡实现过程
逻辑回归
本文档使用 MrDoc 发布
-
+
首页
案例一:鸢尾花分类
### 概述 > `鸢(yuān )尾花分类`相当于机器学习中的Helloworld问题,如果这个问题你能解开了那么说明你机器学习已经入门了。 传统的机器学习任务从开始到建模的一般流程就是:`获取数据 — 数据预处理 — 训练模型 — 模型评估 — 预测,分类`。 我们将根据这个步骤一步一步展开,通过鸢尾花的4个属性预测鸢尾花属于3个种类的哪一类。 ### 01 获取数据 机器学习算法往往需要大量的数据,在skleran中获取数据通常采用两种方式,一种是使用自带的数据集,另一种是创建数据集。sklearn自带了很多数据集,可以用来对算法进行测试分析,免去了自己再去找数据集的烦恼。 > sklearn的自带数据集: > - 鸢尾花数据集 - load_iris() > - 手写数字数据集 - load_digitals() > - 糖尿病数据集 - load_diabetes() > - 乳腺癌数据集 - load_breast_cancer() > - 波士顿房价数据集 - load_boston() > - 体能训练数据集 - load_linnerud() 在这里,我们导入sklearn自带的鸢尾花数据集,该数据集一共包含4个特征变量,1个类别变量,共有150个样本。 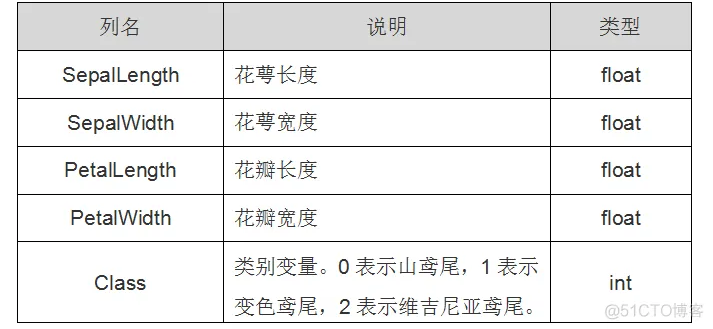 ``` from sklearn.datasets import load_iris iris = load_iris.load_iris() iris_X = iris.data #导入数据 iris_y = iris.target #导入标签如果你想查看数据集对象的属性和方法: print(load_iris().DESCR) ``` ### 02 数据预处理 > 数据预处理阶段是机器学习中不可缺少的一环,它会使得数据更加有效的被模型或者评估器识别。 > 这个阶段主要包括数据预处理和数据集划分两个部分。 当我们拿到一批原始的数据时,需要思考以下问题: - 对连续的数值型特征进行标准化,使得均值为0,方差为1; - 对类别型的特征进行one-hot编码; - 将需要转换成类别型数据的连续型数据进行二值化; - 为防止过拟合或者其他原因,选择是否要将数据进行正则化; - 检查有没有缺失值,对缺失的特征选择恰当方式进行弥补,使数据完整; 2.1 `区间缩放` 区间缩放是将原始数据中的数据缩放到[0,1]范围 ``` from sklearn.preprocessing import MinMaxScaler scaler = MinMaxScaler(feature_range=(0,1)) df_x = scaler.fit_transform(df_x) ``` 2.2 `标准化` 标准化是将数据的分布调整成正态分布,也叫高斯分布,也就是使得数据的均值为0,方差为1 ``` from sklearn.preprocessing import StandardScaler #标准化,返回值为标准化后的数据 StandardScaler().fit_transform(df_x) ``` 2.3 `归一化/正则化` 正则化是将样本在向量空间模型上的一个转换,经常被使用在分类与聚类中。其目的在于样本向量在点乘运算或其他核函数计算相似性时,拥有统一的标准。 ``` from sklearn.preprocessing import Normalizer #归一化,返回值为归一化后的数据 Normalizer().fit_transform(iris.data) ``` 2.4 `特征二值化` 特征二值化是将特征值转换为0或1。 > 例如,在房价预测问题中对于“是否为学区房”这一特征,取值为1表示该房是学区房,反之则为0。 > 在sklearn中可以设置一个阈值,大于阈值的赋值为1,小于等于阈值的赋值为0。 ``` from sklearn.preprocessing import Binarizer #二值化,阈值设置为3,返回值为二值化后的数据 Binarizer(threshold=3).fit_transform(iris.data) ``` 2.5 `One-Hot编码` One-Hot是一种对离散特征值的编码方式,在LR模型中常用到,用于给线性模型增加非线性能力。 对于离散特征,可以采用One-Hot编码将特征表示为一个m维向量,其中m为特征的取值个数。 ``` from sklearn.preprocessing import OneHotEncoder #对IRIS数据集的目标值进行one-hot编码 enc = OneHotEncoder() enc.fit_transform(iris.target.reshape((-1,1))) ``` 2.6 `缺失值处理` 在实际应用中,我们获得的数据往往不完整。对于包含缺失值的样本,通常有以下处理方式: - 删除:删除含缺失值的数据,缺点是可能会导致信息丢失; - 补全:通过已有数据计算相应特征的平均数、中位数、众数等来补全缺失值; - 预测:建立一个模型来“预测”缺失的数据; - 虚拟变量:引入虚拟变量(dummy variable)来表征是否有缺失,是否有补全; ``` from numpy import vstack, array, nan from sklearn.preprocessing import Imputer # 缺失值计算,返回值为计算缺失值后的数据 # 参数missing_value为缺失值的表示形式,默认为NaN # 对数据集新增一个样本,4个特征均赋值为NaN,表示数据缺失 # 参数strategy为缺失值填充方式,默认为mean(均值) Imputer().fit_transform(vstack((array([nan, nan, nan, nan]), iris.data))) ``` 2.7 `数据集拆分` 在预处理阶段,还需要对数据集进行拆分,拆分为训练数据集和验证数据集。 ``` import sklearn.model_selection as sk_model_selection X_train, X_test, y_train, y_test = sk_model_selection.train_test_split(iris_X,iris_y,train_size=1/3,random_state=0) 参数说明: - arrays:样本数组,包含特征向量和标签 - test_size:float-获得多大比重的测试样本, int - 获得多少个测试样本 - train_size: 同test_size - random_state:int - 随机种子(种子固定,实验可复现) - shuffle - 是否在分割之前对数据进行洗牌 ``` ### 03 训练模型 如何为我们的分类问题选择合适的机器学习算法呢? 如果我们以预测结果的准确率为指标,那么最佳的方法就是测试不同的算法,然后通过交叉验证选择最好的一个。 但是,如果我们是为问题找一个合适的算法,则可以根据数据的特点来选择,比如鸢尾花数据集的分类标签有3类,很好的适用于逻辑回归模型。 因此,下面我们将使用sklearn的逻辑回归算法来对数据集进行分析。 ``` from sklearn.model_selection import train_test_split from sklearn.linear_model import LogisticRegression lr = LogisticRegression() lr.fit(X_train,y_train) result = lr.predict(X_test) print('预测的结果', result) print('实际的结果', y_test) ``` ### 04 模型评估和优化 4.1 `模型评估` 模型评估方法:`交叉选择验证法` 1. 是从数据集中按一定比例随机选取若干数据集作为训练集用于模型的训练,并将剩下的数据作为测试集; 2. 将测试集数据的自变量输入模型,并将模型输出的预测值与对应数据的因变量进行比较,判断并统计准确率的方法。 然后根据模型的评估结果来决定如何`优化`: - `过拟合模型` - 在训练集上效果很好,但是在测试集上效果差, - 过拟合的调优思路是,增加训练的数据量,调低模型复杂度; - `欠拟合模型` - 在训练集上效果差; - 欠拟合的调优思路是,提高特征数量和质量,调高模型复杂度; `sklearn` 提供了方法进行交叉验证(模型评估):`cross_val_score` ``` from sklearn.model_selection import cross_val_score from sklearn.model_selection import ShuffleSplit cv_split = ShuffleSplit(n_splits=5, train_size=0.7, test_size=0.2) score_ndarray = cross_val_score(logisticRegression_model, df_x, df_y, cv=cv_split) print(score_ndarray) score_ndarray.mean() cross_val_score参数: - estimator:模型对象; - X:数据; - y:预测数据; - soring:调用的方法; - cv:交叉验证生成器或可迭代的次数; - n_jobs:同时工作的cpu个数(-1代表全部); - verbose:详细程度; - fit_params:传递给估计器的拟合方法的参数; - 返回交叉验证的评分数组 ``` 4.2 `模型优化` 真正考验水平的是根据对算法的理解调节(超)参数,使模型达到最优。 评估后的模型需要进一步调优,调优后的模型需要重新诊断,这是一个反复迭代不断逼近的过程。 sklearn的子模块`GridSearchCV`,是用来查找最优参数的常用方法,只需要把参数的候选集输入进入,就会自动的帮你排列组合,然后选出得分最高的那一组参数。 ``` from sklearn.model_selection import GridSearchCV penaltys=['l1','l2']#l1 或l2正则化 cs = [1.0,1.1,1.2,1.3,1.4,1.5] param_grid = {'penalty':penaltys,'C':cs} #print(param_grid) gsc = GridSearchCV(LogisticRegression(),param_grid) #print(x_train) gsc.fit(X_train,y_train) print('最佳模型参数的评分:',gsc.best_score_) print('最优参数') best_params = gsc.best_estimator_.get_params() print(best_params) for param_name in sorted(param_grid.keys()): print(param_name,':',best_params[param_name]) ``` ### 05 预测 经过优化的模型已经达到最优状态,后面就可以直接用来对新的样本进行预测。 ### 番外 鸢尾花数据集还可以利用其它方式进行分类预测,如KNN,决策树、k-近邻等, 你可以根据自己的需求进行针对训练,还可以比较不同算法下的预测准确度。 ### 参考 > [通过sklearn上手你的第一个机器学习实例](https://blog.51cto.com/u_15310860/3207624)
gaojian
2024年9月14日 15:03
分享文档
收藏文档
上一篇
下一篇
微信扫一扫
复制链接
手机扫一扫进行分享
复制链接
关于 MrDoc
觅思文档MrDoc
是
州的先生
开发并开源的在线文档系统,其适合作为个人和小型团队的云笔记、文档和知识库管理工具。
如果觅思文档给你或你的团队带来了帮助,欢迎对作者进行一些打赏捐助,这将有力支持作者持续投入精力更新和维护觅思文档,感谢你的捐助!
>>>捐助鸣谢列表
微信
支付宝
QQ
PayPal
Markdown文件
分享
链接
类型
密码
更新密码



